C语言基础之预处理机制
写这篇的原因,是前两天半夜拉肚子时,突然一个大二的学弟在QQ上找我问了这个问题,想想人家凌晨还在学习,真是有点惭愧;另一方面,大半年不写C语言,有点儿生疏了,做一下记录。
学弟最近在学习二叉树,他想用C语言实现,大致内容就是在一个名为BiTree.h的头文件里定义了二叉树的节点结构体BNode,另外两个头文件Queue.h和Stack.h由于也需要使用这个结构,所以都分别都有#include "BiTree.h",最后主文件1.c里先后引用了Queue.h和Stack.h。
看起来结构如下图,于是他在VS环境下编译执行时,就会报错 — “BNode”:”struct”类型重定义。
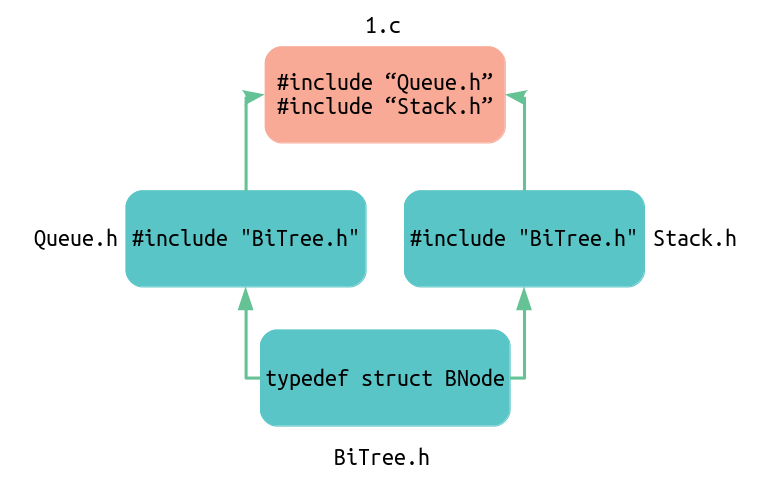
这个问题很容易明白,头文件实际上被源文件包含了两次,所以就会报“重定义”错误。
最直接的解决方法就是条件编译,例如在BiTree.h里这样编写:
1 |
|
这样就消除了多重包含的危险,当头文件第一次被包含时,它被正常处理,_BITREE_H被定义成一个空串,当然也可以改变写法定义成别的。如果头文件再次被包含,由于_BITREE_H已经被定义了,这个头文件的内容将被忽略,_BITREE_H起到了一个标识的作用。
这大概就是条件编译的原理了。
C语言的编译过程包括:预处理、编译、汇编和链接。其中预处理阶段主要是在源码编译前,做一些文本性质的处理操作。例如插入被#include指令包含的文件内容、定义替换#define指令定义的符号、删除注释,以及判断条件编译指令中的条件,以确认某些部分是否要被编译。
1 文件包含
预处理器处理#include指令时,做的事情一般非常简单,删除这条指令,并用被引用文件的内容替换掉它即可,所以上文中出现的重定义问题就是由此引起。
而且如果是头文件被包含,则其中的内容都要被编译,一旦头文件被多个源文件包含,就会被完整重复编译多次,这还是会产生一点儿开销的。因此考虑到效率,以及程序模块化的原则,只把必要的声明放在一个头文件中,用多个粒度小的源文件,代替一个大粒度的源文件,是很有必要的。一方面维护程序时,定位 起来比较方便;另一方面,可以减小意外访问的几率。
1.1 库文件包含
库文件的包含语法一般使用尖括号,例如常见的: #include <stdio.h>。
至于预处理器去哪里寻找库文件,这取决于编译器的文档定义,以及使用的操作系统环境。
当然,大多数编译器也有命令行选项,用以指定头文件函数库的位置,我们可以自己添加目录。
1.2 本地文件包含
本地文件的包含语法一般使用双引号,例如上文的: #include "BiTree.h"。
通常处理本地头文件的方法是在源文件当前的目录查找,如果未找到,则继续查询标准位置。使用相对位置则会在相对于本源文件的位置查找。
C语言的编译器也支持绝对路径的写法,类UNIX系统中绝对路径以/开头,而windows环境以\开头,预处理器如果发现包含的是绝对路径,则会跳过正常的查找顺序,直接查找该绝对路径位置的头文件。
1.3 嵌套文件包含
上文开始处的例子就是文件的嵌套包含,在大型项目中,使用的头文件会非常多,就很难避免这种情况,解决问题的方法可以使用前文中的条件编译。
但是即使如此,预处理依然会读入整个头文件,虽然它的内容最终还是被忽略。但是这个机制会拖慢整个编译速度,所以如果能做到的话,尽量减少头文件的多重包含是最好的。
2 条件编译
编译的时候,如果能够选择某个语句或者代码块是否被编译,会显得比较方便,例如调试代码的部分,只有在调试的时候会被编译,正常使用的时候,又会忽略它们。
C语言中,条件编译机制可以满足这一点,它的基本结构是由#if与#endif构成的判断代码块,如下所示:
1 |
|
如果我们想编译某一块,只要使用#define 常量表达式xxx 1即可,想要忽略则定义成0,这样虽然代码依然保留,但是编译器会根据条件选择性地处理。
另一个方面,这个特性可以用来处理判断一个符号是否被定义,即#if defined(symbol)与#if !defined(symbol),不过我们一般用它的等价形式来写,即#ifdef与#ifndef。
3 宏
由于预处理器处理#define的机制主要是文本替换,所以我们可以通过这个机制将参数替换到文本中,这种实现叫做宏。
一些C语言笔试题里常会考到宏机制中的坑,例如:
1 |
|
这个程序原意是要计算10*(2+2)的结果,但是由于宏函数也是文本替换,所以实际上计算中是这样的:10*2+2,结果就大不相同了,因此定义宏函数时最好加上括号。
为了方便识别,约定俗称的宏写法是全大些字母。
宏函数与普通函数相比,它的执行速度更快,因为普通函数存在函数调用与函数返回的开销;宏函数的参数是替换得来的,与类型无关,但普通函数的参数是类型相关的。
另一方面,宏定义的末尾是不要分号的,因为它被替换为文本之后,这个分号就截断了原有的语句。